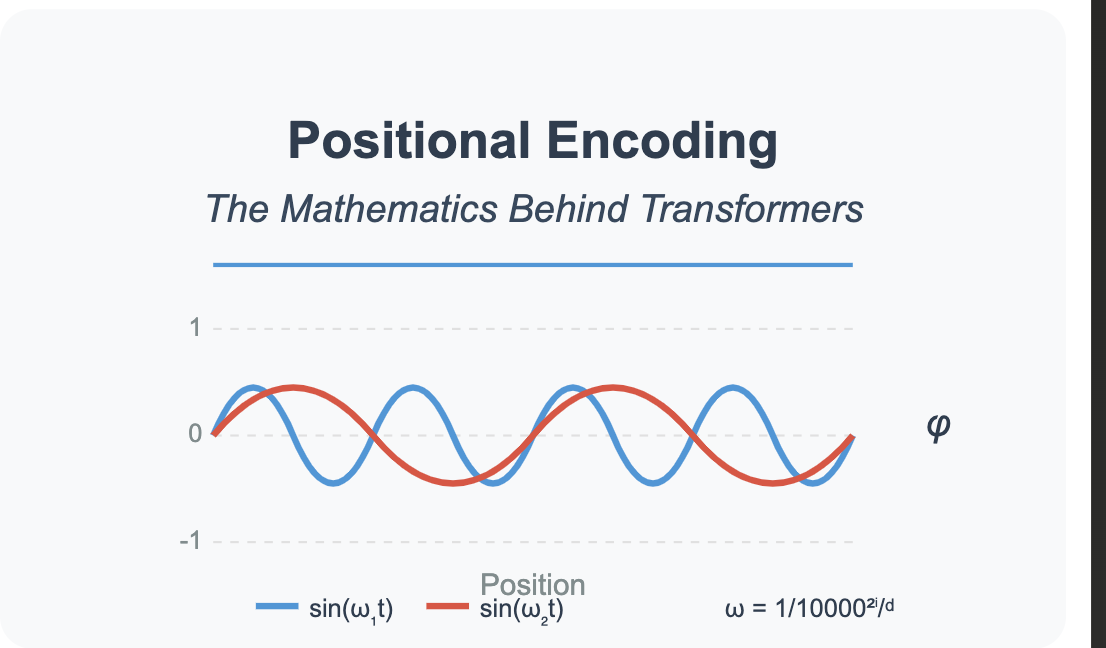
TL;DR. I reimplemented softmax attention and a Performer-style linear attention layer from first principles. My first attempt gave terrible perplexity and no speedup. After aligning the implementations (multi-head Wq/Wk/Wv, 1/√d_head scaling, causal prefix sums, unbiased random features), perplexity became close to softmax on TinyStories. Speed still didn’t beat softmax at seq_len=80—because the linear-time benefits only show up when context length N is large relative to the random-feature rank m and when kernels are well-fused. This post walks through the kernel view of softmax, the fixes that mattered, and a rigorous way to measure the crossover.
Aug 30, 2025